How Spring Swallowed an Exception and Two Weeks of Testing
During our final rounds of testing, we expected to get bugs. But we had no idea we’d be staring at the wrong error…for two weeks.


We were working on a new release for our client, Global Bank.
And now, we were down to the last rounds of tests — which is usually when we expect things to go wrong.
Call it Murphy’s Law..or past experience
And so, we weren’t surprised when we received a bug report from the test team.
But what we didn’t know is that we’d be staring at the wrong error…for two weeks
Trial & Error
Later that day, we got the logs from the test team. Which looked like this:
Caused by: java.lang.NullPointerException at java.io.ByteArrayInputStream.<init>(ByteArrayInputStream.java:118)
at org.jbpm.persistence.processinstance.ProcessInstanceInfo.getProcessInstance(ProcessInstanceInfo.java:178)
at org.jbpm.persistence.processinstance.ProcessInstanceInfo.getProcessInstance(ProcessInstanceInfo.java:169)
at org.jbpm.persistence.processinstance.JPAProcessInstanceManager.getProcessInstance(JPAProcessInstanceManager.java:163)
at org.jbpm.process.instance.ProcessRuntimeImpl.getProcessInstance(ProcessRuntimeImpl.java:283)This error tells us that the byte array was incorrectly persisted during the previous task completion. So our current task completion fails because the byte array is null.
We began to try the usual procedures.
"Maybe we can find other errors in the logs that caused this!” Nope.
“Let’s run a similar process and try to reproduce it” Didn't reproduce.
Finally, we deployed a debug jar to provide more information on how that byte array would get persisted as null. If the test team could reproduce the error, we’d have more information to determine the root cause.
Or so we thought.
Even after they reproduced the bug, we still had nothing useful in the logs. And then Global Bank called..
RING RING
“So…it’s been two weeks since this issue was opened. Do we have an idea what the problem is?”
“Um..no. We’re still trying to determine the root cause”
That's consultant speak for “I have no idea what’s going on”
“Do we know how much longer it’ll take?! Our deadline is next week and half our tests are blocked!”
“....we are working with support & doing everything we can”
They never really have a great reaction to this. But it’s the truth. We were in a bind.
Swallowed Errors, Silent Problems
Later that week, one of the Global Bank devs found out that the error only appeared for certain process types. And they were able to reproduce it locally.
Finally, some good news.
As we stepped through the execution, we saw it enter this little block in the transform() method of the ProcessInstance object:

And then we retrieved the value of e.getMessage():
Caused by: java.io.NotSerializableException: com.globalbank.core.app.ui.common.gblrecord.shared.model.CallCenterImpl
But the transaction committed without any errors in the logs. It didn't make sense.
Until we traced the call up the stack.
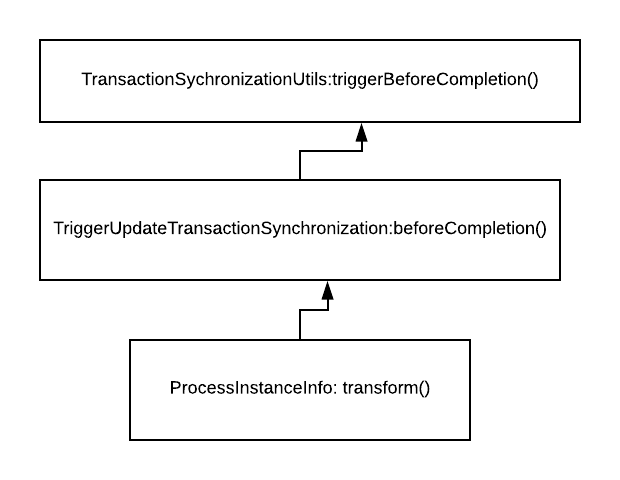
- transform() converts process instance data to a byte stream so it can be saved.
- beforeCompletion() loops through all “dirty” objects and calls transform()
- triggerBeforeCompletion() - loops through TransactionSynchronization objects and calls beforeCompletion()
But the interesting part is in the method body of triggerBeforeCompletion..

Any errors caught in this block will simply be logged. And if there's no error, the transaction manager will commit like it's NO BIG DEAL..
To make matters worse, we use a different logging framework than the default in spring (and we didn't include the package for that class). So none of those messages went to our log files.
But at least now we knew what the problem is.
Always Re-throw the Exception
We could have saved two weeks if the catch block in TransactionSynchronizationUtils included something like:
throw new RuntimeException("Something terrible has happened: " + tsex.getMessage());But I AM SURE there's a good reason why they didn't do that. Anyway, the fix itself took about 30 seconds. The first option was dead simple: Implement Serializable
As it turns out, they didn’t even need that object as a variable. So we just removed it all together.
The day was saved. And although our email said..
“We have found the root cause and deployed a fix”
It always feels more like

Happy Coding,
-T.O.
P.S.: What do you think? How should spring have handled that exception? Let me know in the comments!